| Sigla | Descrição |
|---|---|
| DPPO | Domicílio Particular Permanente Ocupado |
| DPIO | Domicílio Particular Improvisado Ocupado |
| DPO | Domicílio Particular Ocupado (DPPO + DPIO) |
| DPPV | Domicílio Particular Permanente Vago |
| DPPUO | Domicílio Particular Permanente de Uso Ocasional |
| DCCM | Domicílio Coletivo Com Morador |
| DCSM | Domicílio Coletivo Sem Morador |
7 Agregados por Setor Censitário
7.1 Introdução
O produto Agregados por Setores Censitários é um dos resultados do Censo mais amplamente utilizados por pesquisadores, planejadores e gestores públicos. Trata-se de um conjunto de tabelas em que cada linha representa um setor censitário e cada coluna representa uma variável agregada, como o total de moradores, o número de domicílios, as condições de abastecimento de água e esgotamento sanitário e a composição etária da população.
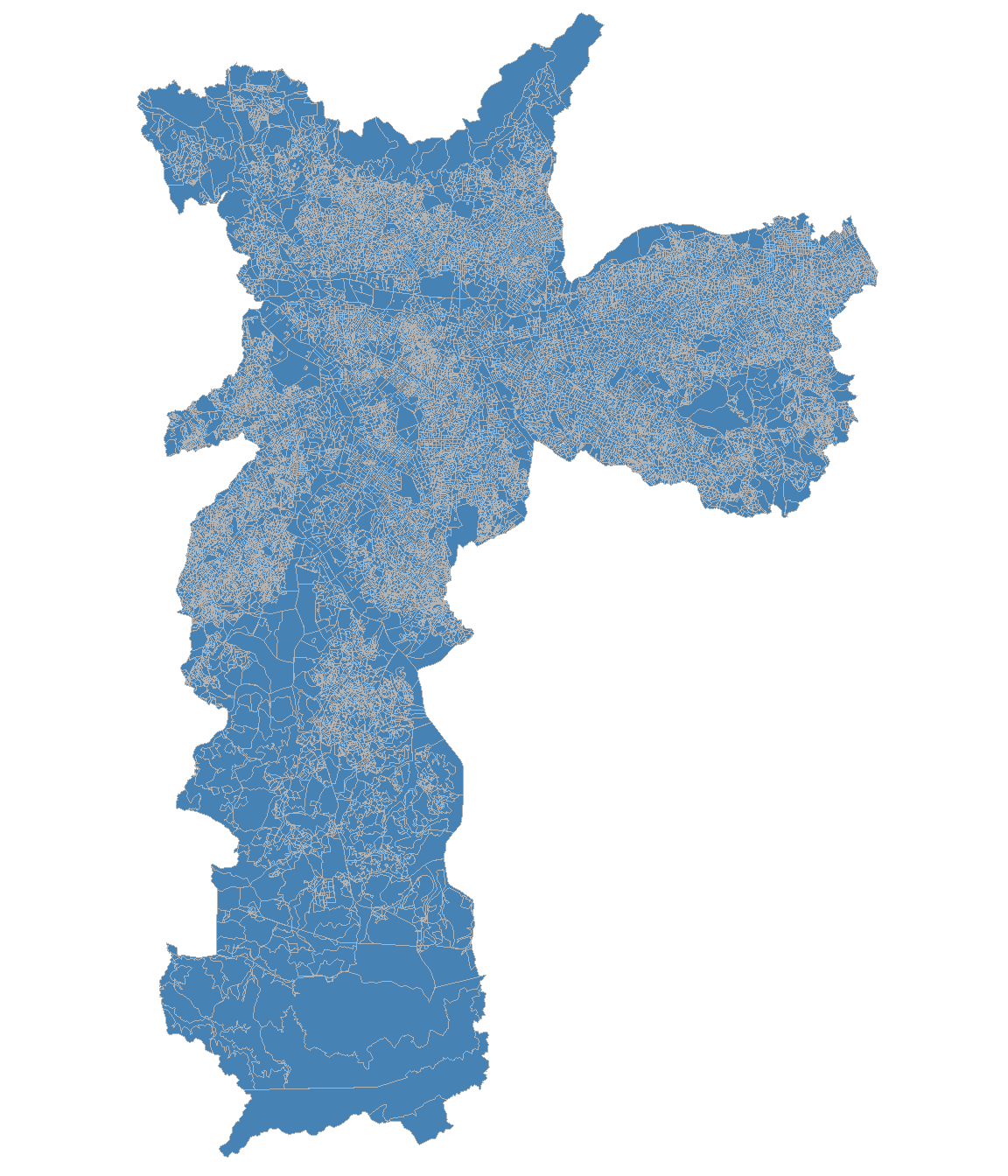
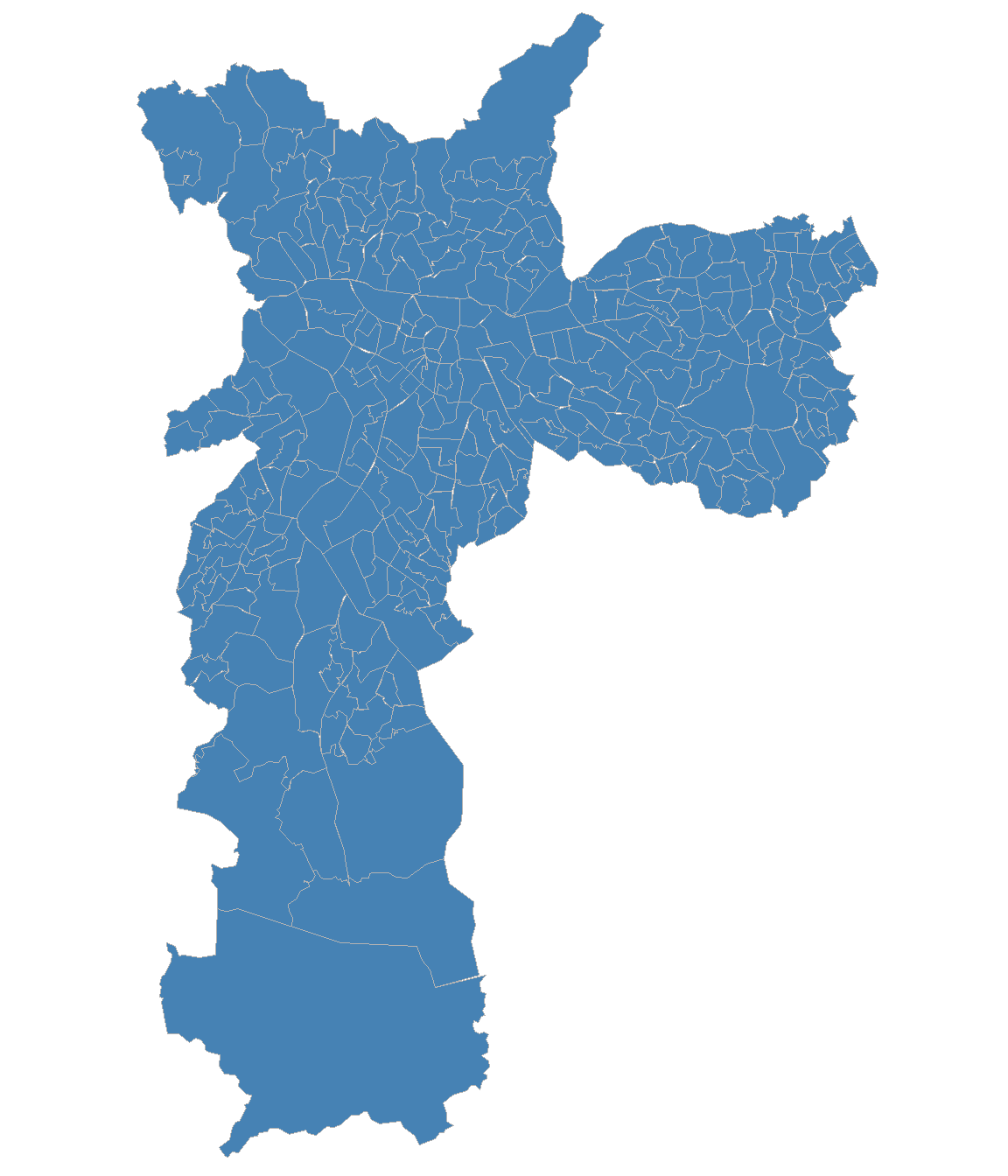
A popularidade desse produto decorre do equilíbrio entre resolução espacial e quantidade de estatísticas disponível por unidade espacial. Enquanto os microdados da amostra permitem análises mais ricas em termos de variáveis (renda, educação, migração), as áreas de ponderação (unidade espacial dos microdados) são muito maiores que os setores censitários. Para se ter uma ideia, no Censo de 2010, o município de São Paulo possuía 5.082 setores censitários, mas apenas 107 áreas de ponderação, conforme ilustra a Figura 7.1. A grade estatística, por sua vez, oferece resolução ainda maior com as quadrículas urbanas de 200 x 200 m, mas contém somente totais de população e domicílio.
O produto que conhecemos hoje tem uma origem mais modesta do que a dimensão atual sugere. A ideia de setor censitário, como a menor unidade espacial de trabalho do Censo, só veio surgir pela primeira vez no Censo de 1950. Antes do Censo 1991, esses arquivos eram concebidos como cadastros de apoio às operações internas do IBGE, com a finalidade de viabilizar a seleção de amostras em pesquisas domiciliares posteriores (IBGE, 2024). Para isso, era suficiente registrar variáveis descritivas da divisão territorial e informações sobre o porte dos setores, como o total de domicílios e estimativas de variância que orientavam a determinação do tamanho das amostras.
No Censo 2000, o IBGE produziu a primeira edição dos agregados por setor censitário, reunindo 527 variáveis sobre características dos domicílios, dos responsáveis e das pessoas residentes, com cruzamentos exclusivamente por sexo. Uma segunda edição, gerada a partir dos microdados do universo, expandiu esse conjunto para mais de 3200 variáveis, organizadas em planilhas separadas por Unidade da Federação.
No Censo 2010, houve uma consolidação deste produto, com divulgação não só no nível dos setores, mas também em Grandes Regiões, Unidades da Federação, Municípios, Distritos, Subdistritos, Bairros e Regiões Metropolitanas (IBGE, 2016). Nesta edição, houve o acréscimo de variáveis relativas a rendimento, tipologia do setor censitário e características do entorno dos domicílios urbanos, totalizando cerca de 3000 variáveis.
No Censo 2022, os arquivos cobrem, pela primeira vez, dados sobre povos indígenas e quilombolas em nível de setor, além dos temas já consolidados de domicílios, demografia, alfabetização, cor ou raça, mortalidade e relações de parentesco, com mais de 3500 variáveis distribuídas em diversos arquivos temáticos (IBGE, 2024). Não obstante, com a redução do questionário Básico (de 34, em 2010, para 26, em 2022), houve perda de variáveis importantes como o rendimento de todos os membros do domicílio.
Antes de partirmos para a exploração destes dados, vamos entender primeiramente alguns conceitos importantes que norteiam o levantamento e a organização destes dados, sobretudo aqueles referentes a moradores e aos tipos de domicílio.
7.2 Conceitos importantes
Para usar corretamente os dados dos agregados, é essencial compreender como o IBGE conceitua moradores e classifica os domicílios. Muitas das variáveis disponíveis nos arquivos temáticos dizem respeito a categorias específicas dessa classificação (como domicílios particulares permanentes ocupados ou domicílios coletivos com morador) e seu significado só fica claro a partir desse sistema conceitual.
O ponto de partida é a definição de morador(a). Para o Censo de 2022, é a pessoa que residia no domicílio na data de referência, ou seja, à meia-noite da transição do dia 31 de julho ao dia 1º de agosto de 2022. Mais especificamente, refere-se a alguém que tem aquele domicílio como local habitual de residência e se encontrava presente no mesmo na data de referência. Todavia, há pessoas que possuem um certo domicílio como local habitual de residência, mas estavam ausentes no período de referência. Nestes casos, esta pessoa ainda é considerada moradora daquele local, caso essa ausência seja inferior a 12 meses e tenha ocorrido por um dos seguintes motivos (IBGE, 2016): viagens (a passeio, serviço, negócio, estudos, etc.); internação em estabelecimento de ensino ou hospedagem em outro domicílio, pensionato, república de estudantes (visando facilitar a frequência durante o ano letivo); detenção, sem sentença definitiva declarada; internação temporária em hospital ou estabelecimento similar; ou embarque a serviço (militares, petroleiros, etc.).
Já o conceito de domicílio refere-se a todo local estruturalmente separado e independente que serve de habitação a uma ou mais pessoas. Os critérios de separação (limitado por paredes, muros ou cercas, com cobertura) e de independência (acesso direto, sem passar por local de moradia de outras pessoas) devem ser atendidos simultaneamente para que um espaço seja classificado como domicílio (IBGE, 2024).1
A Figura 7.2 ilustra a árvore de classificação dos domicílios adotada pelo IBGE.
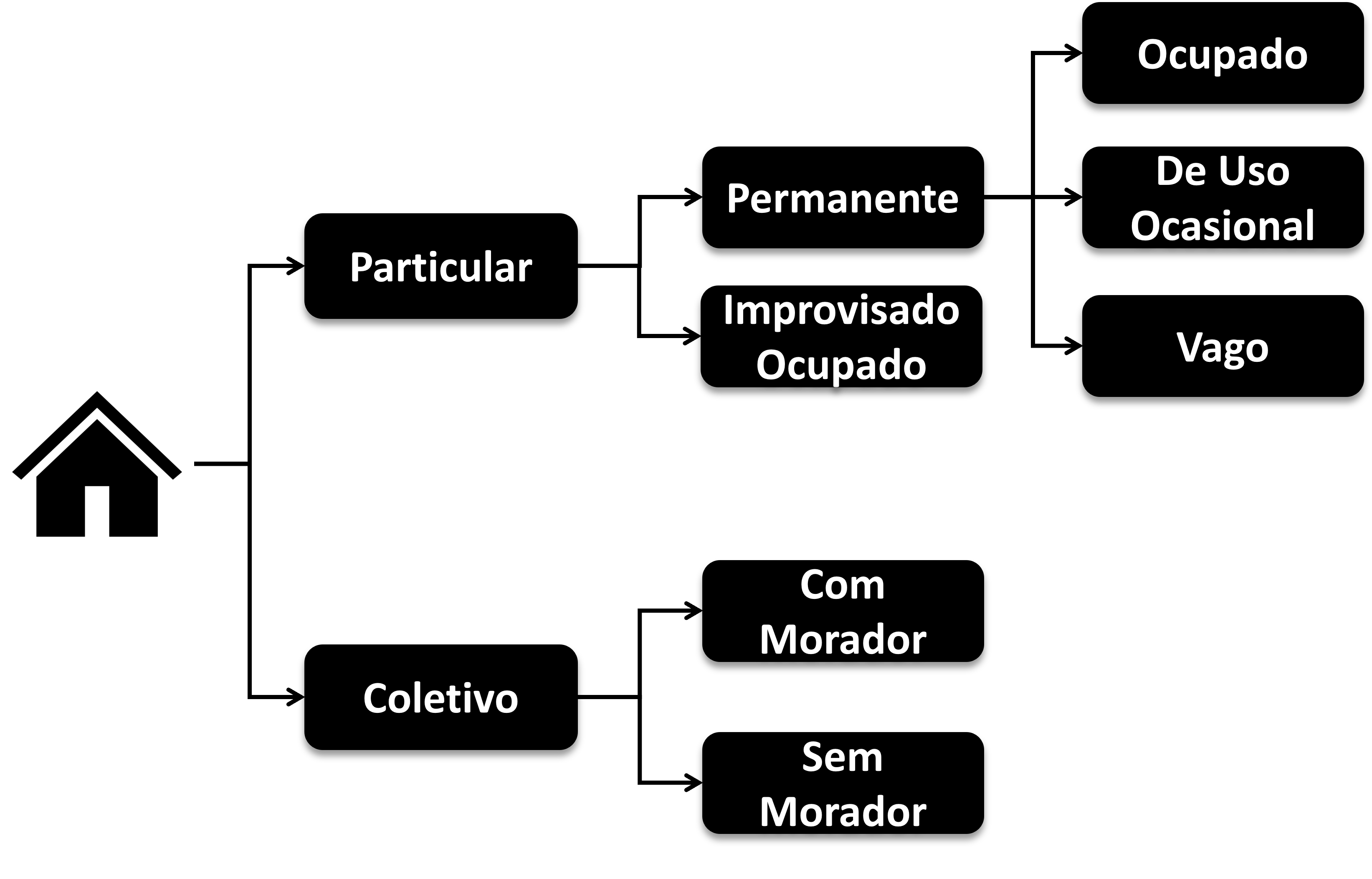
A divisão principal separa os domicílios em dois grandes grupos:
Domicílios particulares são aqueles em que o relacionamento entre os ocupantes é ditado por laços de parentesco, de dependência doméstica ou por normas de convivência. Dentro desse grupo, há duas subcategorias:
- Permanentes: construídos com a finalidade exclusiva de servir como habitação. São classificados em três subtipos2:
- Ocupado: estava habitado na data de referência e a entrevista foi realizada.
- De uso ocasional: usado para descanso de fins de semana, férias ou outro fim, não sendo a residência habitual de nenhum morador.
- Vago: sem morador na data de referência.
- Improvisados: localizados em edificações sem finalidade habitacional (como comércios ou galpões), em espaços públicos (calçadas, praças, viadutos), estruturas móveis ou abrigos naturais, e que estavam ocupados por moradores na data de referência.
Domicílios coletivos são instituições ou estabelecimentos em que a relação entre as pessoas que neles se encontravam era restrita a normas de subordinação administrativa3. Incluem quartéis, hospitais, orfanatos, asilos, presídios4, conventos e alojamentos. São classificados em coletivos com morador e coletivos sem morador.
Como estes termos são utilizados com grande frequência, é comum utilizarmos siglas para representá-los conforme a Tabela 7.1:
7.3 Conteúdo dos Agregados
É importante lembrar que os Agregados por Setores Censitários são produzidos a partir dos resultados do universo, ou seja, das informações coletadas pelo Questionário Básico. Esse questionário é aplicado em todas as unidades domiciliares não selecionadas para a amostra. Para os Censos de 2010 e 2022, estamos falando de aproximadamente 90% dos domicílios entrevistados.
O termo “agregados” indica que as informações não aparecem no nível do indivíduo ou do domicílio, como nos microdados, mas como estatísticas resumidas calculadas para todos os moradores e domicílios de cada setor. Com relação às variáveis de contagem (totais), são disponibilizados valores relativos a variáveis individuais (a exemplo do total de pessoas do sexo feminino ou do número de domicílios do tipo apartamento) ou em cruzamentos de categorias (como o número de pessoas entre 15 e 29 anos que são do sexo feminino e o total de domicílios do tipo casa que possuem abastecimento de água da rede geral). Agregados de média e variância são menos frequentes, sendo especialmente calculados no caso de variáveis de renda/rendimento, seja do(a) responsável do domicílio ou de todas as pessoas do domicílio com 10 anos ou mais (esta última não coletada no Questionário Básico no Censo de 2022).
Essas informações estão organizadas em arquivos temáticos, pois o volume total de variáveis é muito grande para ser distribuído em uma única tabela. As cerca de 3500 variáveis do Censo 2022 são disponibilizadas nos seguintes arquivos:
| Arquivo | Conteúdo | Nº de Variáveis |
|---|---|---|
| Básico | Identificação geográfica e totais estruturais (população, domicílios) | 7 |
| Domicílios (Parte 1) | Características dos domicílios | 89 |
| Domicílios (Parte 2) | Características dos domicílios (continuação) | 406 |
| Domicílios (Parte 3) | Características dos domicílios (continuação) | 148 |
| Pessoas (Alfabetização) | Condição de alfabetização por sexo e idade | 362 |
| Pessoas (Demografia) | Estrutura etária e sexo | 36 |
| Pessoas (Parentesco) | Relação com o responsável pelo domicílio | 182 |
| Mortalidade (Óbitos) | Óbitos no domicílio | 93 |
| Cor ou Raça | Distribuição por cor ou raça | 95 |
| Indígenas (Domicílios e pessoas) | Domicílios e pessoas em territórios indígenas | 1.029 |
| Quilombolas (Domicílios e Pessoas) | Domicílios e pessoas em territórios quilombolas | 951 |
| Entorno (Domicílios, Pessoas e Faces) | Características do entorno dos domicílios urbanos | 105 |
| Renda do Responsável | Rendimento do responsável pelo domicílio | 5 |
Uma limitação importante dos agregados por setor que todo usuário precisa conhecer é a aplicação de regras de sigilo para proteger a identidade dos informantes. Em setores com menos de cinco domicílios particulares permanentes, os valores da maioria das variáveis são substituídos por “x”, indicando omissão (valor ausente). Para os demais setores, células com frequência igual a 1 ou 2 também são suprimidas, pelo risco de que combinações de variáveis com valores muito baixos permitam a identificação indireta de um informante.
Vale ainda mencionar que além dos arquivos no nível de setor censitário, o IBGE também disponibiliza agregações nos níveis de Distritos, Subdistritos e Bairros, facilitando consultas em recortes administrativos mais amplos.
7.4 Analisando os agregados com o censobr
Para obter os dados dos agregados e os microdados da amostra (no próximo capítulo), utilizamos o pacote censobr (Pereira & Barbosa, 2023), que oferece acesso direto a estes arquivos sem necessidade de baixar e descompactar os arquivos do site do IBGE manualmente. Para os agregados, utilizaremos a função read_tracts(), cujos argumentos principais são year, para escolher o ano do censo, e dataset, para especificar qual arquivo temático carregar. Para melhor compreensão, explore a ajuda da função read_tracts() e experimente as opções disponíveis para estes parâmetros. No exemplo abaixo, são baixadas as tabelas dos arquivos Básico e Domicílio (as 3 partes indicadas na Tabela 7.2) para o Censo de 2022:
library(censobr)
# Carregando o arquivo Básico do Censo 2022
sc2022 <- read_tracts(dataset = "Basico", year = 2022)
# Carregando o arquivo de Domicílios do Censo 2022
sc2022_dom <- read_tracts(dataset = "Domicilio", year = 2022)Diversas funções do pacote, incluindo a read_tracts(), foram projetadas para lidar com o desafio do grande volume de dados produzido pelo Censo. Para os agregados de todos os setores censitários do país, por exemplo, estamos nos referindo a um arquivo de 468 mil linhas que pode conter milhares de variáveis. Baixar esse volume toda vez que o script é executado seria inviável. Por isso, por padrão, o argumento cache = TRUE faz com que os arquivos sejam armazenados localmente em formato parquet5 logo após o primeiro download. Nas execuções seguintes, os dados são lidos do disco, sem necessidade de acesso à rede.
Há ainda um segundo mecanismo que torna o fluxo eficiente. Em vez de retornar um data.frame convencional, a função retorna um objeto do tipo Arrow table. A diferença está em quando os dados são realmente carregados na memória. Com um data.frame, tudo é lido imediatamente em RAM. Já um arquivo Arrow funciona de forma lazy (em português, preguiçosa). Quando fazemos operações de manipulação, como filter(), select() ou rename(), nenhum dado é lido, já que o Arrow apenas registra essas operações como um plano de execução. Os dados só são efetivamente carregados quando collect() é chamado ao final. Isso significa que o Arrow pode, ao executar o plano, ler do arquivo apenas as colunas e linhas que sobrevivem aos filtros, ignorando o restante. Com 468 mil setores no Brasil, filtrar pelo município antes de collect() pode reduzir consideravelmente o que é carregado na RAM.
7.4.1 Produzindo tabelas com base em diferentes arquivos de agregados
Com os conceitos estabelecidos, podemos partir para a prática. Nesta seção construímos um painel de mapas com indicadores de adequação habitacional para os setores censitários de Recife (PE). O fluxo que seguiremos combina acesso aos dados do Censo (censobr), manipulação tabular (via tidyverse), operações espaciais (via sf), acesso à cartografia oficial (geobr) e visualização estática (ggplot2):
library(tidyverse)
library(sf)
library(geobr)
library(censobr)
library(mapview)Vamos, preliminarmente, obter o código IBGE do município de Recife para que possamos selecionar somente os setores censitários deste município na nossa base:
recife_ibge <- geobr::lookup_muni(name_muni = "Recife")$code_muniComo as variáveis são identificadas por códigos (como V0001, domicilio01_V00001), consultar o dicionário de dados é sempre o primeiro passo antes de trabalhar com os arquivos. O censobr dá acesso a esse dicionário pela função data_dictionary(). Para o Censo de 2022, isso fará com que um arquivo .xlsx seja aberto em seu computador, onde cada planilha (aba) representa um arquivo dos agregados:
# Dicionário de variáveis dos agregados (Censo 2022)
data_dictionary(year = 2022, dataset = "tracts")
Dica
Mantenha o dicionário aberto enquanto trabalha com os dados. Os códigos de variáveis são baseados no nome do arquivo temático e em um número sequencial, sem nenhuma relação semântica com o conteúdo. Sem o dicionário, não é possível saber o que cada coluna representa.
Para o nosso exemplo, utilizaremos as seguintes variáveis:
| Arquivo | Código original | Nome atribuído | Descrição |
|---|---|---|---|
| Básico | V0001 |
tot |
População total residente |
| Domicílio | domicilio01_V00001 |
dpp |
Domicílios particulares permanentes |
| Domicílio | domicilio02_V00111 |
redger_a |
Dom. com abastecimento de água pela rede geral |
| Domicílio | domicilio02_V00309 |
redger_e |
Dom. com esgotamento via rede geral |
| Domicílio | domicilio02_V00310 |
fossa_s |
Dom. com fossa séptica ligada à rede |
A partir dessas variáveis brutas, derivamos dois indicadores de inadequação. A definição de adequação segue o critério adotado pelo Índice de Vulnerabilidade Social (IVS) do Ipea (Costa & Marguti, 2015). Utilizaremos dois indicadores do IVS Infraestrutura Urbana, um relacionado à abastecimento de água inadequado, quando o abastecimento de água não provém de rede geral, e outro relacionado à esgotamento sanitário inadequado, quando o esgotamento sanitário não é realizado por rede coletora ou fossa séptica:
perc_agua_inadeq: proporção de domicílios sem abastecimento de água pela rede geral (1 - redger_a / dpp)perc_esg_inadeq: proporção de domicílios com esgotamento inadequado, ou seja, sem rede geral nem fossa séptica ligada (1 - (redger_e + fossa_s) / dpp)
library(censobr)
# Leitura dos arquivos Básico e do Domicílio dos agregados:
sc2022 <- read_tracts(dataset = "Basico", year = 2022)
sc2022_dom <- read_tracts(dataset = "Domicilio", year = 2022)
# Produção da base de dados para análise
sc_recife_2022 <- sc2022 |>
filter(code_muni == recife_ibge) |> # Filtrando somente recife
select(code_tract, code_muni, V0001) |> # Selecionando somente colunas de interesse
rename(tot = V0001) |> # Renomeando a população total
# Junção dos dois arquivos de agregados:
left_join(
sc2022_dom |>
filter(code_muni == recife_ibge) |> # Filtrando somente recife
select(code_tract, code_muni, # Selecionando somente colunas de interesse
domicilio01_V00001,
domicilio02_V00111,
domicilio02_V00309,
domicilio02_V00310)
) |>
# Atribuição de novos nomes às variáveis de interesse para análise:
rename(
dpp = domicilio01_V00001,
redger_a = domicilio02_V00111,
redger_e = domicilio02_V00309,
fossa_s = domicilio02_V00310
) |>
collect() |> # Observe que a base de dados é trazida para memória somente neste momento
# Cálculo dos indicadores finais com base no IVS:
mutate(
perc_agua_inadeq = 100 * (1 - redger_a / dpp),
perc_esg_inadeq = 100 * (1 - (redger_e + fossa_s) / dpp)
)O resultado é um data.frame com os setores censitários de Recife. Podemos verificar o total de setores e as variáveis disponíveis:
nrow(sc_recife_2022)[1] 468099names(sc_recife_2022)[1] "code_tract" "code_muni" "tot" "dpp"
[5] "redger_a" "redger_e" "fossa_s" "perc_agua_inadeq"
[9] "perc_esg_inadeq" 7.4.2 Integrando a geometria com o geobr
Com os dados de Recife já em memória, o próximo passo é integrar os polígonos dos setores. Baixamos a malha com read_census_tract() e fazemos a junção com os indicadores pela coluna code_tract:
recife_sc_geo <- geobr::read_census_tract(
code_tract = recife_ibge,
simplified = FALSE
)
recife_sc_geo <- recife_sc_geo |>
left_join(sc_recife_2022, by = "code_tract")7.4.3 Visualizando os resultados em mapas
Com a camada espacial pronta, usamos o ggplot2 para gerar mapas coropléticos que mostram a distribuição espacial dos indicadores por setor. Os quatro mapas a seguir mostram, respectivamente, a população total, o total de domicílios particulares permanentes, a proporção de domicílios sem acesso à rede de água e a proporção de domicílios com esgotamento inadequado.
NotaEscala de cor com transformação de raiz quadrada
O mapa da Figura 7.3 utiliza uma escala de cor com transformação de raiz quadrada (trans = "sqrt"). O motivo é a presença de um setor com valor muito acima dos demais, o Complexo Prisional do Curado, com 5.799 indivíduos, que é quase o triplo do segundo setor mais populoso. Em uma escala linear, a paleta de azuis se concentraria quase toda entre zero e esse valor extremo, deixando o restante do município com tons muito claros e sem distinção visual. A transformação raiz quadrada comprime os valores altos e expande os baixos na escala de cor, sem precisar remover o setor ou tratar o valor como ausente. Esse recurso é especialmente útil quando poucos locais concentram valores muito acima da distribuição geral, como presídios, hospitais de grande porte ou terminais de carga em mapas de população.
ggplot(recife_sc_geo) +
geom_sf(aes(fill = tot), color = NA) +
scale_fill_distiller(palette = "Blues", direction = 1,
name = "Pop. total",
na.value = "gray90",
trans = "sqrt",
labels = scales::label_number(big.mark = ".")) +
coord_sf(expand = FALSE) +
theme_minimal() +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())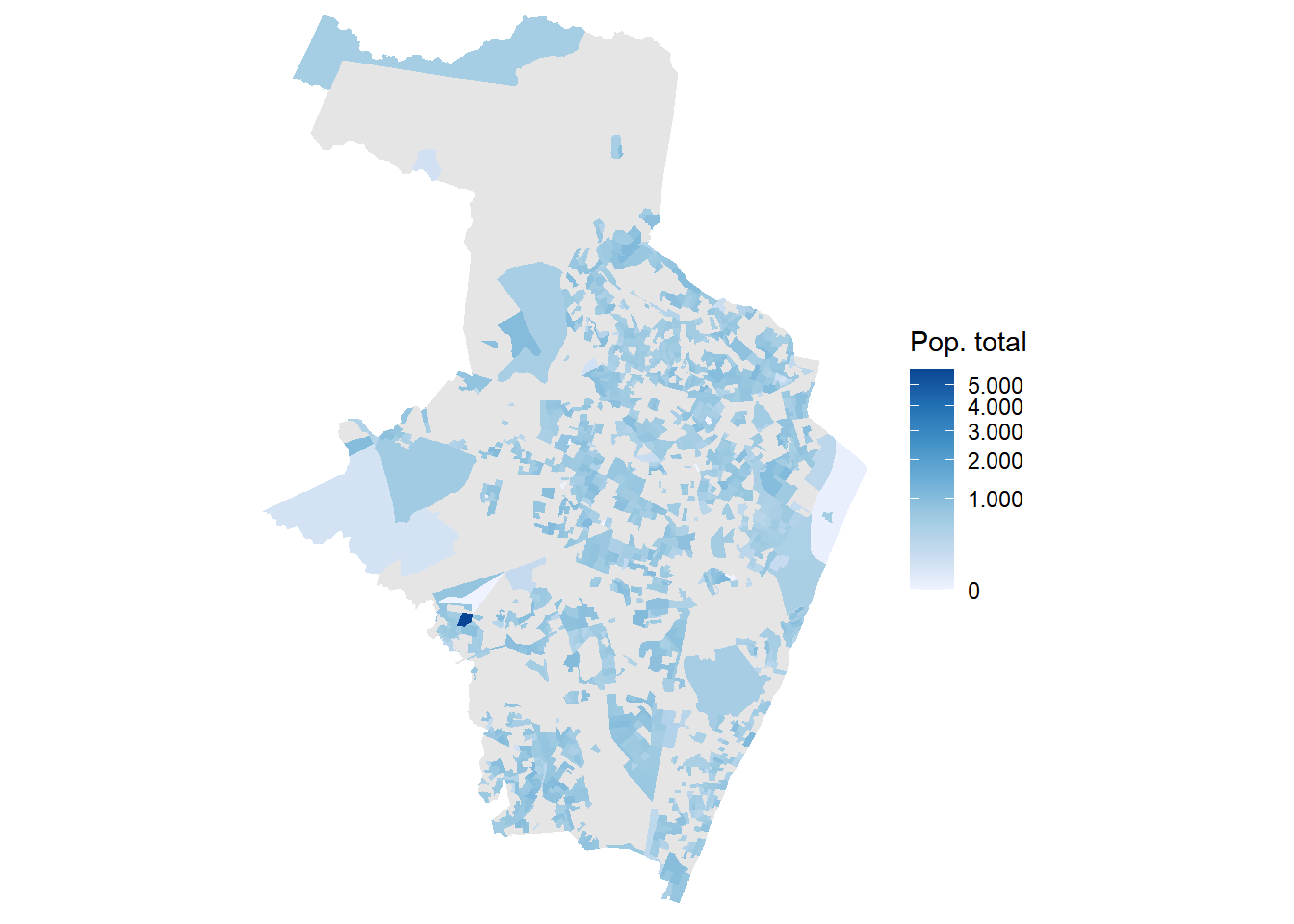
ggplot(recife_sc_geo) +
geom_sf(aes(fill = dpp), color = NA) +
scale_fill_distiller(palette = "Purples", direction = 1,
name = "Dom. part.\npermanentes",
na.value = "gray90") +
coord_sf(expand = FALSE) +
theme_minimal() +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())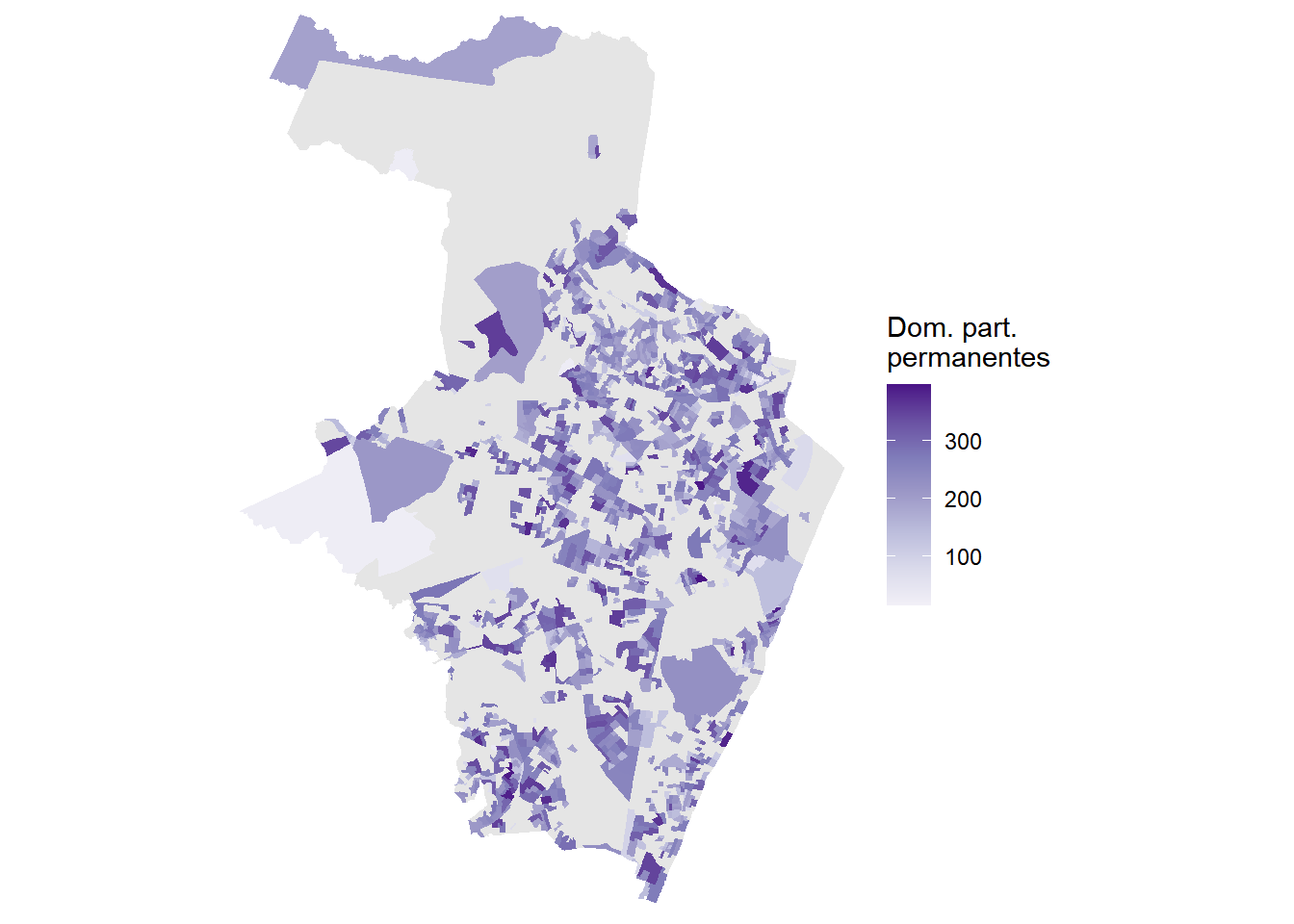
ggplot(recife_sc_geo) +
geom_sf(aes(fill = perc_agua_inadeq), color = NA) +
scale_fill_distiller(palette = "Reds", direction = 1,
name = "% sem água\nda rede",
na.value = "gray90") +
coord_sf(expand = FALSE) +
theme_minimal() +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())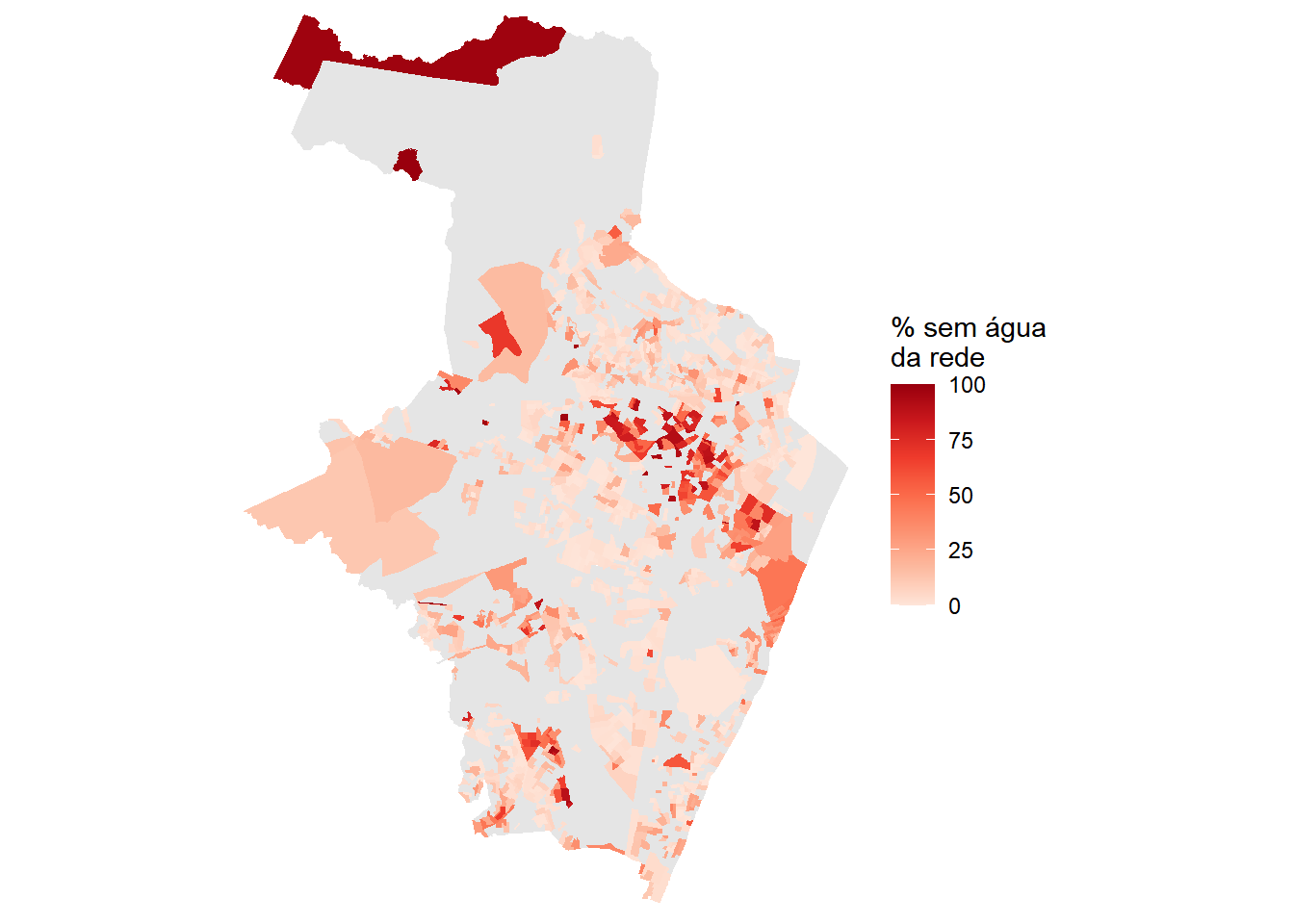
ggplot(recife_sc_geo) +
geom_sf(aes(fill = perc_esg_inadeq), color = NA) +
scale_fill_distiller(palette = "YlOrRd", direction = 1,
name = "% esgoto\ninadequado",
na.value = "gray90") +
coord_sf(expand = FALSE) +
theme_minimal() +
theme(axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())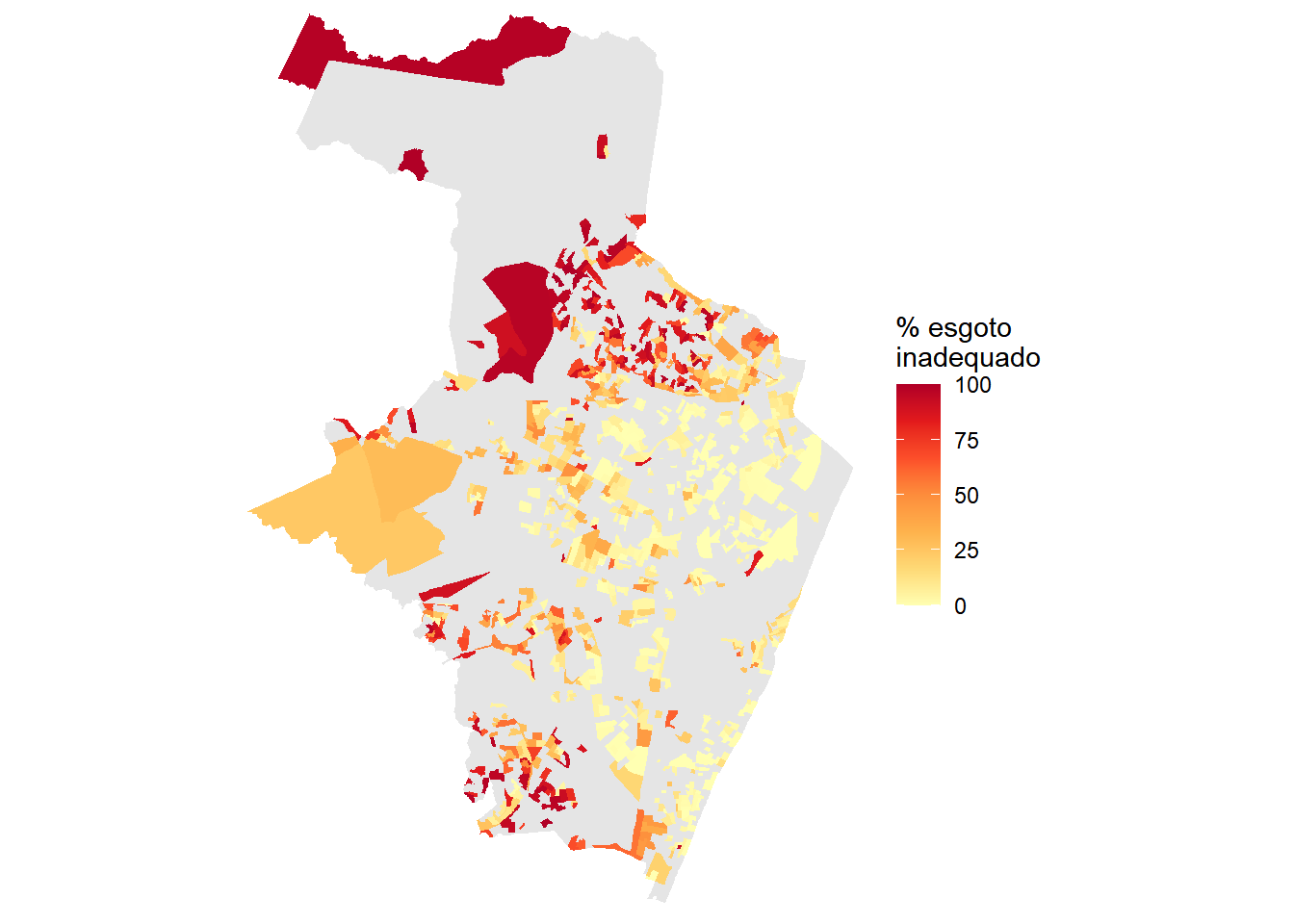
Os mapas revelam padrões de desigualdade intraurbana típicos das grandes metrópoles brasileiras. Setores com maior proporção de domicílios sem acesso adequado a saneamento tendem a se concentrar em determinadas áreas do município, enquanto outros setores apresentam cobertura praticamente universal. Esse tipo de visualização é um ponto de partida valioso para diagnósticos de infraestrutura urbana.
7.5 Produção de mapas personalizados das variáveis dos Agregados
Os setores censitários são a unidade espacial de coleta do IBGE, desenhados para facilitar o trabalho dos recenseadores. Isso significa que seus limites não necessariamente coincidem com as unidades de análise que os pesquisadores desejam utilizar. Em muitos contextos, é mais conveniente trabalhar com unidades padronizadas para propósitos analíticos específicos, a exemplo de distritos sanitários, subprefeituras, áreas de risco da defesa civil, distritos policiais ou zonas de tráfego.
Em outras aplicações, pode ser mais interessante recorrer ao uso de grades regulares como o GeoHash ou a grade hexagonal H3. Ambos têm em comum o fato de particionarem a superfície terrestre em células indexadas de forma hierárquica, permitindo representar localizações, agregar dados espaciais e realizar análises em diferentes níveis de resolução. No caso do GeoHash, essa indexação é feita a partir de uma subdivisão sucessiva do espaço em retângulos, codificados por cadeias alfanuméricas, nas quais o aumento do número de caracteres corresponde a um refinamento da resolução espacial.
A grade hexagonal H3 também divide a superfície terrestre em células hexagonais indexadas por cadeias alfanuméricas. Sua estrutura é organizada em 16 níveis hierárquicos de resolução, nos quais cada célula de um dado nível pode ser subdividida em sete células do nível seguinte, preservando, em geral, a forma hexagonal. As resoluções mais usadas em análises urbanas são a 8 (área média de ~0,74 km², lado de ~460 m) e a 9 (~0,10 km², lado de ~174 m). No exemplo da Figura 7.7 abaixo, é possível observar a sobreposição de grades hexagonais H3 para as resoluções 7, 8 e 9, por exemplo, tendo parte do município de Salvador como pano de fundo. Em termos práticos, a resolução 7 produz células mais agregadas, a 8 representa um nível intermediário e a 9 gera uma malha mais detalhada, com hexágonos progressivamente menores à medida que a resolução aumenta.
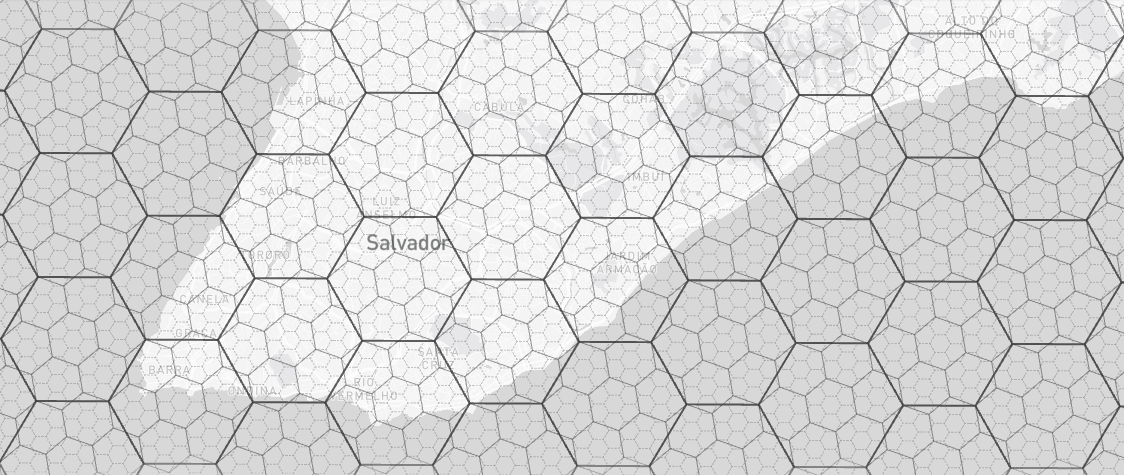
Em relação às grades retangulares convencionais, grades hexagonais apresentam algumas vantagens topológicas relevantes (Brodsky, 2018). Em primeiro lugar, os hexágonos têm apenas um tipo de vizinho (os que compartilham aresta), enquanto quadrados têm dois (aresta e vértice), o que exige conjuntos distintos de coeficientes em análises. Em decorrência desse aspecto, o centro de cada hexágono é equidistante dos seis vizinhos, ao contrário das grades quadradas, onde os vizinhos diagonais estão ~41% mais distantes que os laterais. Além disso, anéis concêntricos de hexágonos aproximam círculos com mais fidelidade do que anéis quadrados, tornando a análise de zonas de influência e proximidade mais natural.
No Brasil, um caso de uso de destaque das grades hexagonais é o Projeto Acesso a Oportunidades do IPEA (Pereira et al., 2022), que disponibiliza dados censitários e de uso do solo em grade H3 de resolução 9 para diversas cidades brasileiras, integrando informações sobre distribuição espacial da população por idade, sexo, renda e raça, além da localização de empregos e serviços públicos.
Contudo, transferir dados de setores censitários para outras unidades espaciais não é uma tarefa trivial. A abordagem mais simples, que distribui os dados proporcionalmente à área de sobreposição entre os setores e as unidades-alvo, ignora que a população não está distribuída uniformemente pelo espaço. Uma quadra residencial densa e um parque urbano podem estar no mesmo setor e ter a mesma área, mas a população se concentra na quadra.
Uma possível solução para esse problema é a interpolação dasimétrica (dasymetric interpolation), uma técnica que usa informações auxiliares sobre a localização da população para guiar a redistribuição espacial dos dados. No contexto do Censo brasileiro, o Cadastro Nacional de Endereços para Fins Estatísticos (CNEFE, um dos produtos do Censo que abordaremos em um outro capítulo mais adiante) oferece exatamente esse insumo: a localização de cada endereço visitado pelos recenseadores. Em vez de assumir distribuição uniforme por área, a interpolação dasimétrica distribui os dados do setor pelos pontos de endereços que estão dentro dele e, em seguida, agrega os valores dos pontos que caem em cada unidade-alvo, conforme ilustrado na Figura 7.8.
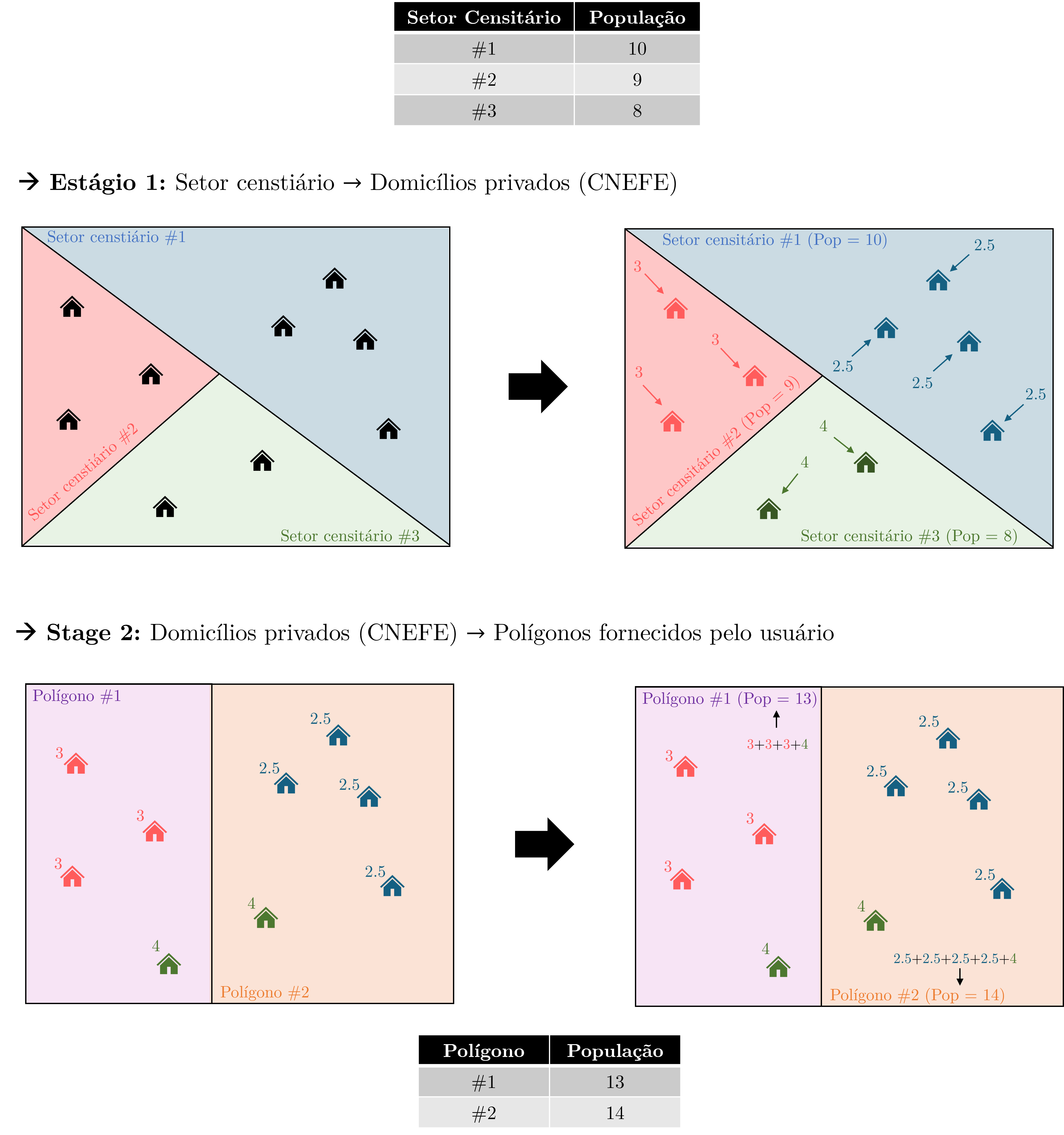
O método funciona de maneira diferente para dois tipos de variáveis:
- Variáveis de totais (como população total ou quantidade de indivíduos do sexo feminino): o total do setor é dividido igualmente entre os pontos de endereço elegíveis dentro dele. Cada unidade espacial alvo recebe, então, a soma dos valores dos pontos que caem dentro de seus limites. Corresponde exatamente ao que é demonstrado na Figura 7.8.
- Variáveis de média (como renda média domiciliar): o valor médio do setor é atribuído a cada ponto. A unidade espacial alvo recebe a média dos valores dos pontos que estão dentro dela.
7.5.1 O pacote cnefetools
O pacote cnefetools implementa esse fluxo de trabalho de forma integrada, combinando automaticamente os dados do CNEFE com os agregados por setor para produzir estimativas em outras configurações espaciais. Suas duas funções principais são:
tracts_to_h3(): transfere variáveis dos setores para uma grade de hexágonos H3 na resolução desejada.tracts_to_polygon(): transfere variáveis dos setores para qualquer tipo de malha de polígonos fornecida pelo usuário.
O argumento vars de ambas as funções aceita os nomes de variáveis listados na Tabela 7.4. Para cada variável, o pacote identifica automaticamente o tipo de alocação adequado (total ou média) com base em uma tabela de referência interna (tracts_variables_ref).
cnefetools. Fonte: cnefetools::tracts_variables_ref.
| Variável | Código IBGE | Descrição | Tipo |
|---|---|---|---|
pop_ph |
V00005 | Moradores em dom. particulares permanentes ocupados | Total |
pop_ch |
V00007 | Moradores em dom. coletivos com morador | Total |
male |
V01007 | Pessoas do sexo masculino | Total |
female |
V01008 | Pessoas do sexo feminino | Total |
age_0_4 |
V01031 | Pessoas de 0 a 4 anos | Total |
age_5_9 |
V01032 | Pessoas de 5 a 9 anos | Total |
age_10_14 |
V01033 | Pessoas de 10 a 14 anos | Total |
age_15_19 |
V01034 | Pessoas de 15 a 19 anos | Total |
age_20_24 |
V01035 | Pessoas de 20 a 24 anos | Total |
age_25_29 |
V01036 | Pessoas de 25 a 29 anos | Total |
age_30_39 |
V01037 | Pessoas de 30 a 39 anos | Total |
age_40_49 |
V01038 | Pessoas de 40 a 49 anos | Total |
age_50_59 |
V01039 | Pessoas de 50 a 59 anos | Total |
age_60_69 |
V01040 | Pessoas de 60 a 69 anos | Total |
age_70m |
V01041 | Pessoas de 70 anos ou mais | Total |
race_branca |
V01317 | Pessoas de cor ou raça branca | Total |
race_preta |
V01318 | Pessoas de cor ou raça preta | Total |
race_parda |
V01320 | Pessoas de cor ou raça parda | Total |
race_amarela |
V01319 | Pessoas de cor ou raça amarela | Total |
race_indigena |
V01321 | Pessoas de cor ou raça indígena | Total |
n_resp |
V06001 | Responsáveis por dom. particulares permanentes ocupados | Total |
avg_inc_resp |
V06004 | Rendimento nominal médio mensal dos responsáveis com rendimentos | Média |
7.5.2 Interpolando para hexágonos H3
O código a seguir gera uma grade de hexágonos H3 (resolução 8) para Recife com a variável de população total em domicílios particulares permanentes (pop_ph):
library(cnefetools)
hex_recife <- tracts_to_h3(
code_muni = 2611606,
h3_resolution = 8,
vars = "pop_ph"
)mapview(hex_recife,
zcol = "pop_ph",
layer.name = "Habitantes (estimativa)",
col.regions = hcl.colors(100, palette = "YlOrRd") |> rev())7.5.3 Interpolando para zonas de tráfego
Um caso de uso especialmente relevante no planejamento de transportes é a transferência dos dados do Censo para zonas de tráfego. Zonas de tráfego são as unidades espaciais básicas usadas nos modelos de demanda por transporte. Cada zona é delimitada de modo que os deslocamentos entre origens e destinos diferentes possam ser representados como fluxos entre pares de zonas. Na prática, seus limites são definidos para que os padrões de mobilidade sejam relativamente homogêneos dentro de cada zona, respeitando divisores naturais como vias expressas, linhas férreas e rios. Por isso, essas fronteiras podem não coincidir com os dos setores censitários, o que torna necessária alguma forma de interpolação para alocar variáveis socioeconômicas às zonas.
Para a Região Metropolitana de São Paulo, as zonas de tráfego são definidas pela Pesquisa Origem-Destino (OD) realizada pelo Metrô de São Paulo. Na sua edição de 2017, este arquivo geográfico pode ser acessado pelo pacote odbr. Como a pesquisa cobre toda a região metropolitana (39 municípios), a base de dados inclui o campo NomeMunici que permite filtrar apenas as zonas para determinados municípios. No exemplo abaixo, escolhemos as zonas do município de São Paulo-SP para interpolar a população total (pop_ph) e a população com 70 anos ou mais (age_70m) para essas zonas. Logo em seguida, produzimos um mapa da variável relativa à população de 70 anos ou mais nas zonas de tráfego, originalmente advinda dos agregados:
library(cnefetools)
library(odbr)
# Zonas de tráfego da Pesquisa OD 2017 — Região Metropolitana de SP
sp_zones <- read_map(
city = "Sao Paulo",
year = 2017,
geometry = "zone"
)
# Filtrando apenas as zonas do município de São Paulo
sp_zones_muni <- sp_zones |>
filter(NomeMunici == "São Paulo") |>
sf::st_make_valid()
# Transferindo população total e idosos dos setores para as zonas
sp_zones_census <- tracts_to_polygon(
code_muni = 3550308,
polygon = sp_zones_muni,
vars = c("pop_ph", "age_70m")
)
# Proporção de população com 70 anos ou mais por zona
sp_zones_ratio <- sp_zones_census |>
filter(pop_ph > 0) |>
mutate(pct_70m = age_70m / pop_ph)
mapview(sp_zones_ratio, zcol = "pct_70m", layer.name = "Prop. pop. 70+")mapview(sp_zones_ratio,
zcol = "pct_70m",
layer.name = "Prop. pop. 70+")7.5.4 Ressalvas com o uso da interpolação do cnefetools
A interpolação dasimétrica implementada no cnefetools representa um avanço em relação à interpolação por área convencional, mas não elimina todos os problemas de inferência espacial. É importante ter em mente duas limitações relevantes antes de interpretar os resultados.
A primeira diz respeito à falácia ecológica. O método assume que todos os domicílios de um setor censitário são razoavelmente uniformes em relação à variável interpolada, pois cada ponto de endereço dentro do setor recebe o mesmo valor médio ou a mesma fração do total. Na prática, um setor pode conter domicílios de perfis socioeconômicos distintos, e a alocação uniforme ignora essa heterogeneidade interna. O resultado é que a variável estimada para a unidade-alvo reflete a média do setor de origem, não necessariamente a composição real dos endereços que caem dentro daquela unidade. Quanto menor e mais homogêneo for o setor censitário em relação à variável de interesse, menor será esse viés.
A segunda limitação refere-se às unidades nas bordas municipais. Quando uma zona de tráfego (ou hexágono) cruza o limite do município, ela recebe apenas os endereços do município informado em code_muni. Os endereços do município vizinho não são incluídos, pois o cnefetools opera sobre o CNEFE de um município de cada vez. Isso significa que as estatísticas calculadas para unidades na borda representam apenas a parcela que pertence ao code_muni informado. Em análises de regiões metropolitanas, onde os limites municipais cruzam frequentemente áreas contínuas de ocupação, essa limitação deve ser levada em consideração na interpretação dos resultados.
7.6 Exercícios
Utilizando o fluxo apresentado na Seção 7.4.1, calcule para o município de Fortaleza (CE) a proporção de domicílios com coleta de lixo direta (consulte o dicionário para identificar a variável correspondente no arquivo Domicílio). Visualize o resultado em um mapa com
mapview.Selecione duas variáveis de diferentes arquivos temáticos (por exemplo, uma de demografia e uma de domicílios) e construa um mapa coropléfico com
ggplot2para um município de sua escolha. Inclua título, legenda e fonte nos atributos do mapa.Para o município de Salvador, compare os mapas de inadequação de água e de esgoto produzidos neste capítulo. Em quais regiões do município as duas inadequações ocorrem simultaneamente? Como você interpretaria esse padrão em termos de planejamento urbano?
Pesquise a documentação do pacote
cnefetoolse identifique quais variáveis estão disponíveis para interpolação dasimétrica comtracts_to_h3(). Aplique a função para gerar uma grade H3 (resolução 7) para Salvador (BA) com pelo menos duas variáveis e discuta esses resultados.
Nas áreas indígenas, este conceito é flexibilizado para abranger a diversidade de domicílios de grupos variados↩︎
pode-se considerar ainda a presença de um quarto subtipo Ocupado sem entrevista, consistindo de domicílio que estava habitado na data de referência, mas os moradores estavam ausentes ou se recusaram a responder. Para esses casos, o IBGE aplica imputação estatística com base em domicílios semelhantes do mesmo setor↩︎
condomínios residenciais, prédios residenciais, cortiços e repúblicas de estudantes não são considerados domicílios coletivos↩︎
detento é considerado morador da penitenciária se houver alguma condenação, ou se a detenção da detenção tiver ultrapassado 12 meses↩︎
um formato de arquivo colunar que, ao contrário do CSV (que grava os dados linha a linha), organiza-os coluna a coluna, o que viabiliza compressão muito mais eficiente e leitura seletiva de apenas as variáveis necessárias↩︎